Introduction
Toybox is designed to enable an improved understanding of small sample learning and hand object scene interaction. This dataset was developed by a group of researchers from AIVAS Lab, Vanderbilt University.
About the Dataset
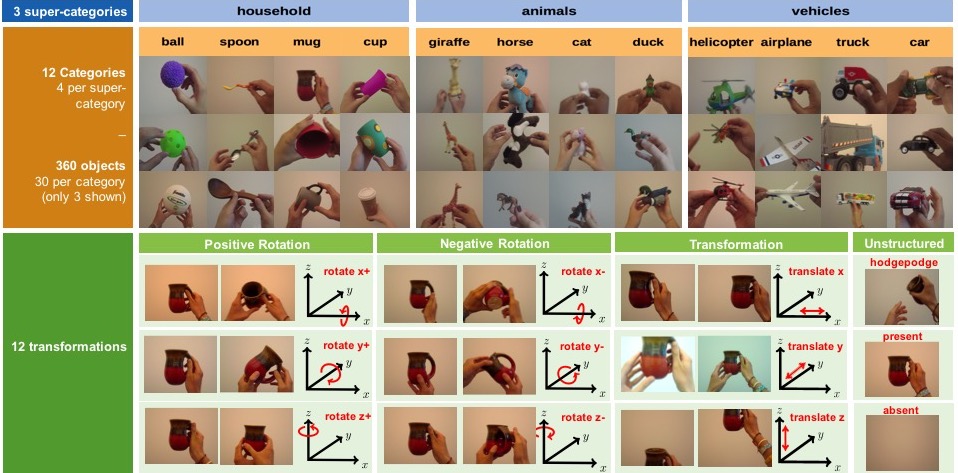
Toybox contains 12 categories, roughly grouped into three super-categories:
- household items (cup, mug, spoon, ball)
- animals (duck, cat, horse, giraffe)
- vehicles (car, truck, airplane, helicopter).
To maximize the usefulness of Toybox for comparisons with studies of human learning, all 12 of these categories are among the most common early-learned nouns for typically developing children in the U.S. (http://wordbank.stanford.edu/)
All videos were recorded using Pivothead Original Series wearable cameras, which are worn like a pair of sunglasses and have the camera located just above the bridge of the wearer’s nose. Specific settings of the camera are shown below:
- video resolution set to 1920x1080
- frame rate set to 30 fps
- quality set to SFine
- focus set to auto
- exposure set to auto.
Download
The dataset can be downloaded from Zenodo and is split into three super-categories. The entire dataset is 110GB. Each chunk of the dataset can be downloaded as a TAR archive that contains videos for the four object categories in a given super-category.
For each of the four object categories, the archive contains 30 folders, each corresponding to an individual object in that category, labeled by the name and ID of the object, for example: “airplane_01”, “airplane_02”, etc. Each labeled folder contains 12 video files in MP4 format, for the 12 different video transformations of the object.
-
Part 1 - Animals: https://zenodo.org/record/1289936#.WyPJ4HXwbCJ
-
Part 2 - Households: https://zenodo.org/record/1290019#.WyPQyHXwZhE
-
Part 3 - Vehicles: https://zenodo.org/record/1290757#.WyPdwnXwbCI
Publication
If you wish to cite this work, please use the citation below:
- Xiaohan Wang *, Tengyu Ma *, James Ainsoon, Seunghwan Cha, Azhar Molla, Xiaotian Wang, and Maithilee Kunda.
Seeing Neural Networks Through a Box of Toys: The Toybox Dataset of Visual Object Transformations.
arXiv preprint arXiv:1806.06034, 2018.
@misc{1806.06034,
Author = {Xiaohan Wang and Tengyu Ma and James Ainooson and Seunghwan Cha and Xiaotian Wang and Azhar Molla and Maithilee Kunda},
Title = {Seeing Neural Networks Through a Box of Toys: The Toybox Dataset of Visual Object Transformations},
Year = {2018},
Eprint = {arXiv:1806.06034},
}
-
Xiaohan Wang *, Tengyu Ma *, Azhar Molla, Seunghwan Cha, James Ainsoon, Xiaotian Wang, and Maithilee Kunda.
An Object Is More Than a Single Image: The Toybox Dataset of Visual Object Transformations.
The 4th Vision Meets Cognition Workshop at Computer Vision and Pattern Recognition (CVPR), 2018. -
Xiaohan Wang, Fernanda M. Eliott, James Ainooson, Joshua H. Palmer, Maithilee Kunda.
An Object Is Worth Six Thousand Pictures: The Egocentric, Manual, Multi-Image (EMMI) Dataset.
International Conference on Computer Vision (ICCV), Egocentric Perception, Interaction, and Computing (EPIC) Workshop, 2017.
@InProceedings{Wang_2017_ICCV,
author = {Wang, Xiaohan and Eliott, Fernanda M. and Ainooson, James and Palmer, Joshua H. and Kunda, Maithilee},
title = {An Object Is Worth Six Thousand Pictures: The Egocentric, Manual, Multi-Image (EMMI) Dataset},
booktitle = {The IEEE International Conference on Computer Vision (ICCV) Workshops},
month = {Oct},
year = {2017}
}
Team
Core Team Members (alphabetical)

James Ainooson

Seunghwan Cha

Maithilee Kunda

Fernanda M. Eliott

Joshua Palmer

Tengyu Ma

Azhar Molla

Xiaohan Wang

Xiaotian Wang
Other Contributors (alphabetical)

Ellis Brown

Aneesha Dasari

Max Degroot

Joseph Eilbert

Joel M. Michelson

Soobeen Park

Harsha P. Vankayalapati
Acknowledgement
Thanks also to Linda Smith, Chen Yu, Fuxin Li, and Jim Rehg for early discussions influencing this research. This research was funded in part by a Vanderbilt Discovery Grant, “New explorations in visual object recognition,” and by NSF award #1730044.